In the practice of production, there is often a need to optimize specific processes in terms of performance, memory, etc. There can be used a variety of algorithms and always focus on the business idea and customers’ wishes. As for processing big data, computing power plays a significant role here. That is why it is so important to find a tool that speeds up this process, and that is where the DASK framework helps.
The DASK cluster configuration, pending functions, and decorators will be broached, in this article. You will be given some simple examples of reading .csv files, defining data frames, and wrapping source functions into decorators, and the usefulness of metrics monitoring will be shown as well. Also, there will be used a real case to describe the use of DASK in production tasks.
If you are a specialist in Big Data or Data Science, this material will help you quickly expand, create new projects, and implement existing ones based on the DASK framework. In addition, you will be able to apply the developed modules in cloud services and platforms.
In 10 Years the Amount of Data has Increased Significantly and Continues to Grow
Let’s remember the average device user in 2010. Often he is at his computer, never letting go of his smartphone and sitting on several social networks. Today, data flow comes from a much larger number of channels. Dozens of social networks and services, smart watches and glasses, TV and game consoles, and even smart cars are all capable of collecting and processing data, downloading the firmware, etc. Hence the rapid growth of big data.
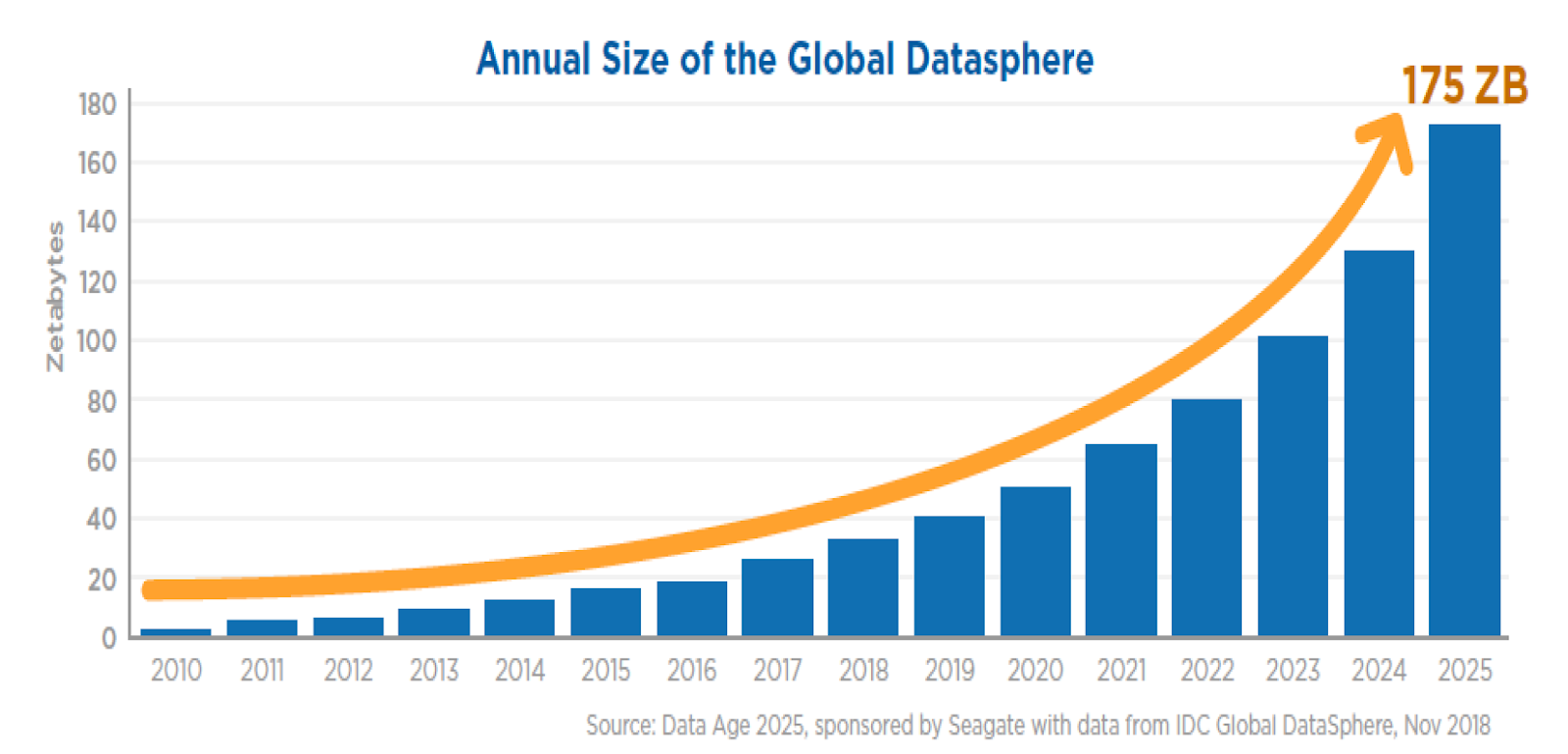
According to the International Data Corporation, by 2025, the amount of data generated around the world (the so-called global datasphere) is expected to grow to about 170 zettabytes, which is 10 times more than the statistics of ten years ago.
There is also an evolution of computational instances—CPU and graphics gas pedals. It becomes more and more challenging to increase the number of transistors per unit area. However, this cannot be said about the graphics processing unit. According to statistics, over 10 years, the performance growth, in this case, behaves almost linearly. However, in recent years, more powerful graphics gas pedals can efficiently and quickly cope with computer vision, data mining, time series prediction, and NLP tasks. Five years ago, all of these were considered virtually unsolvable.
Why DASK?
Every data scientist has built data pipelines (data pipeline, ML pipeline, or a combination of them). Before training the model or using it in inference, the data needs to be processed. If there are many of them, DASK is the right place to do it.
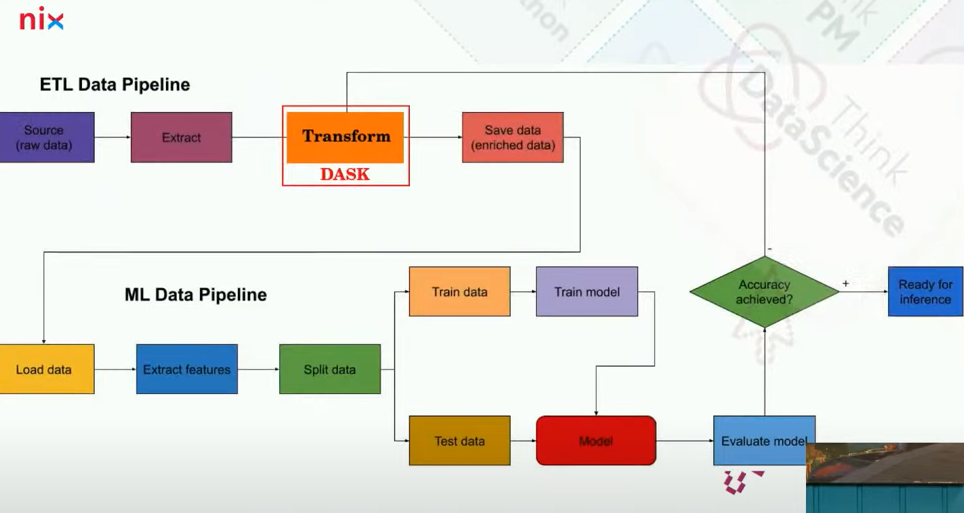
DASK is easy to understand. The framework has an extensive documentation with lots of examples. In the transformation loop (Extract, Transform, Load), DASK takes place in the transformer point. The framework can be used as an in-point to transform some data into other data. For example, raw data has been transformed into enriched data and put into a repository to eventually use for model training.
DASK Features and Benefits
DASK has pandas frameworks under the hood. It supports docker containers, different data formats (.csv, .parquet, .json) and can work with database dumps. DASK also supports decorators, moving functions from the category of normally-executed functions to the category of deferred ones. This framework offers parallel execution and, importantly, scalability. You can accumulate a certain number of compute instances, distribute the tasks set by the DASK graph, and initialize the compute instances. This way, you can significantly improve your performance.
Unlike conventional multiprocessing, which allows you to parallelize a task simply, DASK enables you to look at performance metrics. And this is important when building and analyzing a data pipeline for significant data transformation. After all, when you build a pipeline, you need to clearly understand which modules and elements are working efficiently and where the bottleneck occurs. With DASK, you can see these metrics and determine what to do next.
In addition, DASK can be integrated with Google Cloud Platform, Azure, and AWS, allowing for automatic scaling of compute instances. In addition, many customers often turn to these cloud platforms, so you can solve many business problems with DASK and thereby cover your customers’ needs.
Three Ways to Configure a DASK Cluster
Let’s say right away: the following is an example of a local cluster. If you are interested in how to build a DASK cluster, you can follow the links at the end of the article to find out all the details. As for the example, everything is simple here. Call the client, then select the local cluster option and specify the number of workers and the number of threads per our workers. Done —the cluster is set up.
from dask. distributed import Client, LocalCluster local_cluster = LocalCluster (n_workers = 4, threads_pet_worker=2) client = Client (local_Cluster) print (client) ✓ 1.3s <Client: ‘tcp://127.0.0.1:43271’ process=4 threads=8, memory=7.76 GiB>
Now let’s see how DASK can turn ordinary functions into delayed ones, using the example of a function that performs the summing of list items. In the first case, an ordinary function is executed, in the second case, the function is wrapped in a delayed decorator, and in the third case, the compute module is called.
import dask import dask.dataframe as ddf from dask.delayed import delayed ✓ 1.5s
The execution time of this block takes a second and a half.
def get_sum (data):
sum = Ø
for current_item in data:
sum + = current_item
return sum
data = [1, 2, 3, 4]
res = get_sum (data)
print (res)
✓ 0.5s
10
@delayed
def get_sum (data):
sum = Ø
for current_item in data:
sum + = current_item
return sum
data = [1, 2, 3, 4]
res = get_sum (data)
print (res)
✓ 0.4s
Delayed (‘get_sum-e2a760b3-b2c1-4cec-b4a7-a8584bd33ece’)
@delayed
def get_sum (data):
sum = Ø
for current_item in data:
sum + = current_item
return sum
data = [1, 2, 3, 4]
res = get_sum (data).compute ()
print (res)
✓ 0.5s
10
It’s necessary to point out a few crucial points. First, the result of the function is 10, which is essentially the sum of all the elements. Second, the execution time reaches 0.4-0.5 seconds on each module. But if you look closely at the second module, you’ll notice: there’s actually no result here. Instead, there is a DASK dataframe object. Why does this happen? When you wrap the original function in a decorator, it actually becomes lazy and does nothing. To make a function do something useful, you have to force it. This is why the compute method is called(as in the third code block)—so that the computation happens.
How .csv Files are Read in DASK
DASK has almost the same syntax as pandas. If you are familiar with this tool, you can easily master DASK to optimize your data processing pipelines. This can be clearly seen in the following example:
import pandas as pd import dask. dataframe as ddf ✓ 0.2s %time pd_df = pd/read_csv( “/home/serhii/Projects/Dask/example.csv”) ✓ 3.2s CPU times: user 1.81 s, sys: 549 ms, total: 2.36 s Wall time: 3.16 s %time dk_df = ddf.read_csv (“/home/serhii/Projects/Dask/example.csv”) ✓ 0.7s CPU times: user 57.6 s, sys: 20.7 ms, total: 78.3. s Wall time: 667 s %time dk_df = ddf.read_csv (“/home/serhii/Projects/Dask/example.csv”).сompute () CPU times: user 1.35 s, sys: 366 ms, total: 1.72 s Wall time: 1.24 s
This example uses semi-synthetic customer data, which is placed in a .csv file. Let’s try to subtract them. In one case, in the first line, this is done with a pandas data frame and takes 2.36 seconds. In the second case, it goes to the DASK data frame and writes the data into the DASK data frame. This takes about 78 milliseconds. You might think this means DASK does the job much faster, but in fact, it doesn’t—don’t forget the keyword compute. 78 milliseconds is the creation of a graph instruction for a pending task. To get DASK to do the task, you need to call compute, which is what happens in the penultimate line. The time required to read the data is then already 1.72 seconds. There is, of course, a gain, but not so radical.
In this example, an ordinary single .csv file is read, but this is not a good approach for DASK. It is better in practice to use parquet files, which allow distributing load between compute instances or processor cortices more efficiently. If there is no such possibility, you should at least make a partitioned .csv. In this case, DASK will look at each partition separately and read it in parallel threads. But even if you work with a single .csv file, you can get a small profit.
Merging Data Frames
For example, let’s take demonstration data to evaluate the performance of the join data frame. Create two DASK dataframes: DASK Dataframe 1 and DASK Dataframe 2. Then create the resulting data frame, where you specify the keyword merge and how you measure. In that case, by name field:
columns_name = [ “NAME” , “VALUE”] test_data_1 = [ [ “name 1”, 1], [ “name 2”, 2], [ “name 3”, 3], [ “name 4”, 4], [ “name 5”, 5] ] test_data_1 = [ [ “name 1”, 11], [ “name 7”, 7], [ “name 3”, 33], [ “name 8”, 8], [ “name 9”, 9] ] dask_df1 = ddf.from_pandas (pd.DataFrame(data = test_data_1, columns = columns_name), npartitions=2) dask_df2 = ddf.from_pandas (pd.DataFrame(data = test_data_2, columns = columns_name), npartitions=2) joined_df = dask_df1 = merge (dask_df2, left_on = “NAME”, right_on = “NAME”) print (joined_df.head()) ✓ 0.2 s
DASK supports indexing. This means you can put a binary key on each column of the original data frame. Eventually, DASK will re-sort the data, and the data frames will merge very quickly. The code below is the same, but there have been added two more lines that specify the two set index merge parameters:
columns_name = [ “NAME” , “VALUE”] test_data_1 = [ [ “name 1”, 1], [ “name 2”, 2], [ “name 3”, 3], [ “name 4”, 4], [ “name 5”, 5] ] test_data_1 = [ [ “name 1”, 11], [ “name 7”, 7], [ “name 3”, 33], [ “name 8”, 8], [ “name 9”, 9] ] dask_df1 = ddf.from_pandas (pd.DataFrame(data = test_data_1, columns = columns_name), npartitions=2) dask_df2 = ddf.from_pandas (pd.DataFrame(data = test_data_2, columns = columns_name), npartitions=2) dask_df1 = dask_df1.set_index ( ‘NAME’). persist () dask_df2 = dask_df2.set_index ( ‘NAME’). persist () joined_df = dask_df1.merge (dask_df2, right_index = True, left _index = True”) print (joined_df.head()) ✓ 0.2 s
Set the index on the name field of the first data frame and similarly on the name field of the second data frame, and then merge. Only in this case you do not set the right on and left on, but the right index and the left index, which are bitmaps.
Metrics Monitoring
This is one of the coolest features of DASK. When working with big data, getting lost in what went wrong is easy. You have multi-threaded or spread loads across different compute instances, but performance has increased insignificantly, remained the same, or dropped altogether. In this situation, it is worth turning to the DASK dashboard and looking at monitoring metrics. You can see what is going wrong, which module or function is taking most of the time, where the data leakage is, or where bottlenecks are forming. The information obtained will allow you to make a suitable decision on how to optimize this module.
The DASK dashboard is available on the local host and includes several tabs: status, workers, tasks, system, profiler, and status graph. Below is a brief run of each of them.
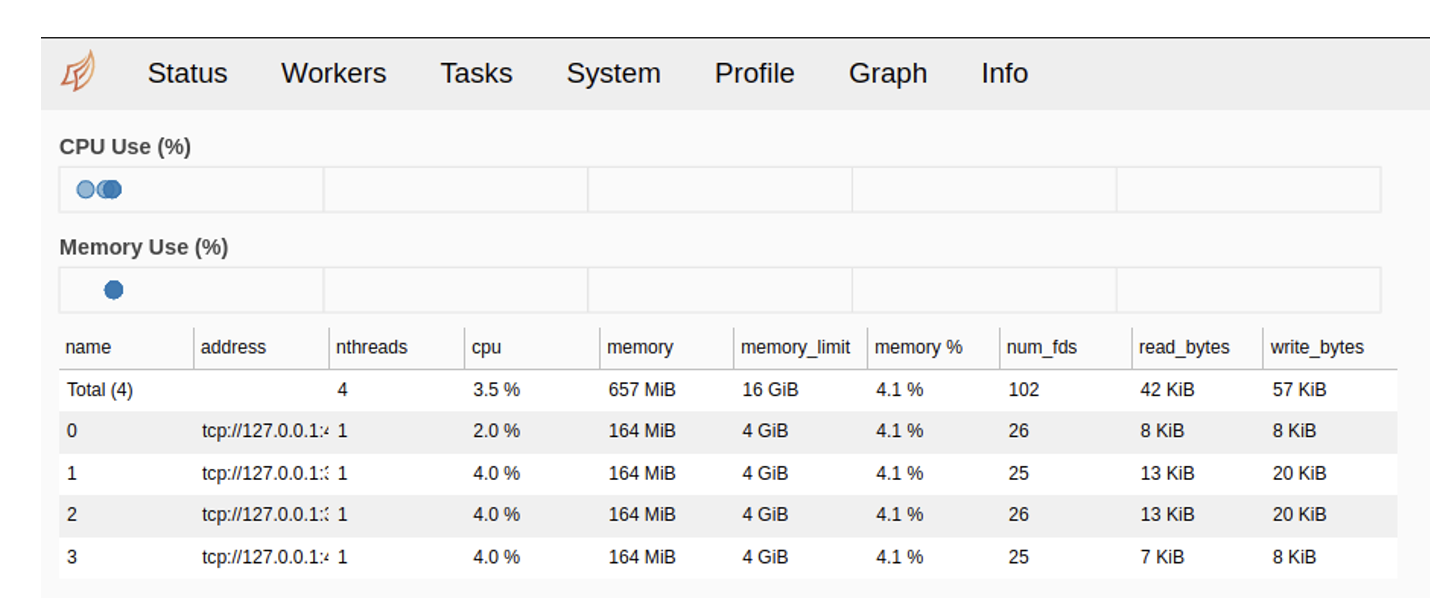
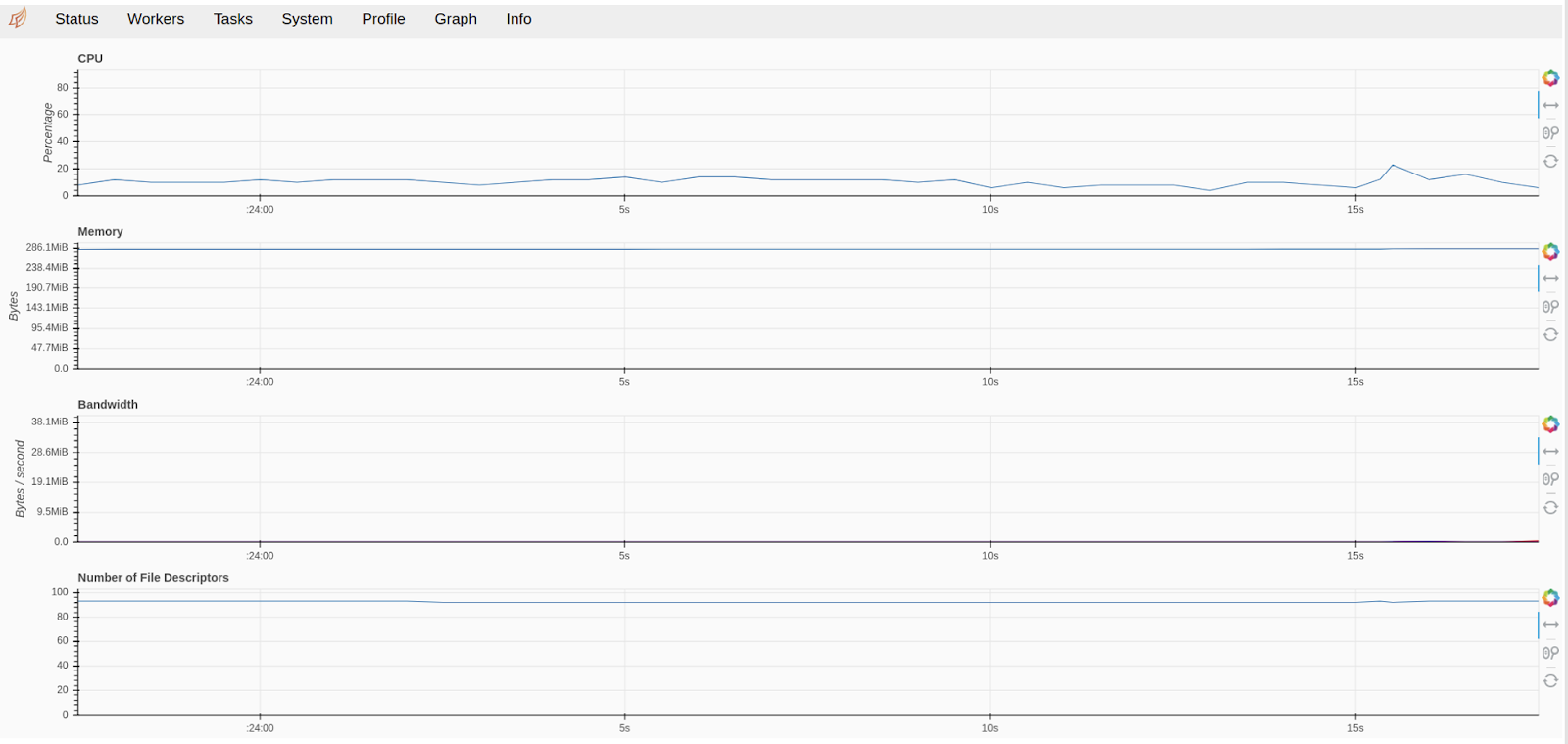
The first tab is Status. It displays how much memory each worker consumes, how the process of loading and execution of individual tasks goes and also shows delays in transferring control between tasks. Based on this information, you can draw proper conclusions about the performance of individual modules and build hypotheses to improve them.
The next tab is Workers. This shows compute instances that allow you to perform a particular task. In this tab, you can see in detail how a particular worker is loaded and how the load is distributed among the compute instances.
Then there is the System tab, which allows you to analyze how much RAM is consumed and what swap is involved.
The Profile screen is shown below. The rectangles in the picture are the execution times of a particular module in the form of a Python function or decorator that is part of the data pipeline. That is, you can see how long each module takes to execute:
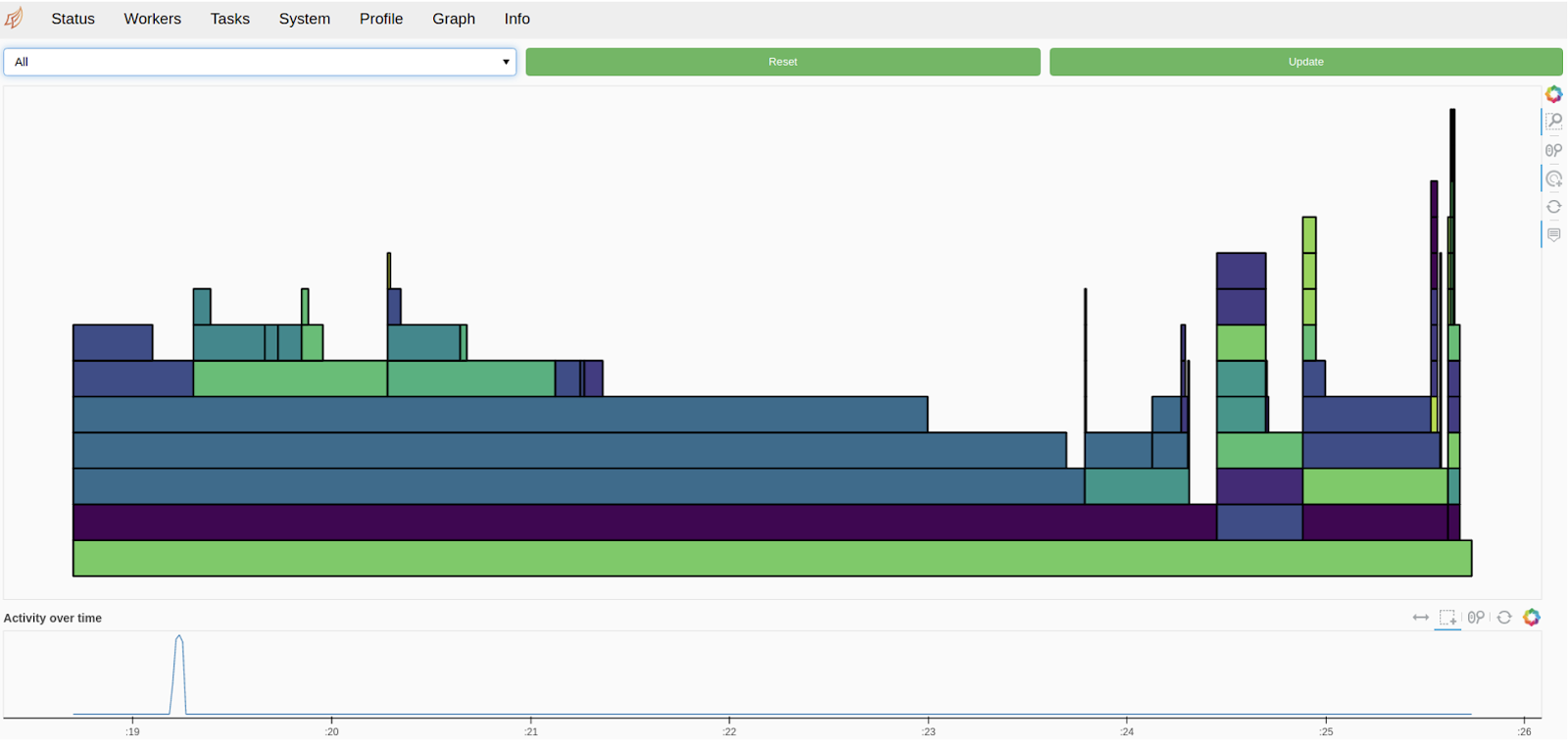
Moreover, DASK knows how to analyze the nested structure of these functions. Imagine this situation: you have a normal function with a subsequent nested function that calls a third function. Even if you use the decorator to wrap the function at the top level, DASK can break down the tasks, analyze the break-down graph internally, and then understand how the function will be executed down to the minor level. This way, you can understand how tasks are generally completed and which module to look at.
An Example of Using DASK in Practice
A company from the United States collected and provided data on car dealerships. The data came from car dealerships (about car purchases or buyers) and users who were buying cars themselves. Specialists had the task to process quite a lot of such data in a short period. The diagram below shows the interaction scheme and their role in data processing.
There were two main difficulties. First, everything had to go up quickly. Second, the team needed to deploy it in the customer’s existing ecosystem. They had Python code and customer-installed data processing logic. The data was in the form of URLs that included UTM parameters. They contained information about where the user went, what sites they came from, what companies they visited, etc. All of this is scratched and sent for analysis.
Using multiprocessing was inconvenient, but it was necessary to somehow divide the load on compute instances. How can the team use DASK in such a situation? The data could be provided either in .csv format or, more often, in a database dump. Between the latter and the database, where the results were fluffed, they just implemented DASK. The input data was called Raw Data, and the fluffed data was called Enrich Data. Here’s how it was implemented in the code:
def batch (input_data):
sub_results = [ ]
for current_sample in input_data:
sub_results. append (referParsev3 (*current_sample))
current_result_df = pd. DataFrame (data=sub_results, columns=set_columns_name)
current_values = current_result_df
return current_values
Pay attention to the refererParseV3 function. It is the one responsible for the customer’s logic, and it should have been optimized and accelerated.
Next, you will have an example of a loop where batch data of 500 records occurs, and this batch data is stored in the variable current date. This is followed by a batch function, which wraps the customer logic. It translates these batches into a module where the logic is processed, and then the response is returned:
batch_size = 500
Prepare batch to calculation
number_iteration = int (add_DF,shape [0] / batch_cize )
for index in range (number_iteration);
if index ! = number_iteration - 1:
сurrent_data = values [index * batch_size: index* batch_size + batch_size]
else:
сurrent_data = values [index * batch_size]
Make batch function as delayed. It means that it will be calculated later
result_batch_refererV3 = dask. delayed (batch) (current_data)
result_fillna = dask. delayed (fillna_def) (result_batch_refererV3)
result_batch = dask. delayed (write_db_file) (result_fillna)
Create stack of delayed functions
batches_result.append (result_batch)
time start = time. time ()
result = dask. compute (*batches_result)
time_end = time. time () - time_start
For the DASK data frame to be able to handle this logic efficiently, experts need to make the function delayed. To do this, they create a result batch refererV3, wrap the butch function in a delayed decorator, and then pass it as input data to current data. That is, they get the data broken down by batch. Finally, the result is put into the resulting batch referrer parse v3. The result is sent to the next data processing module. In this case, the module is called fillna_def. It is designed to clean the data from empty values:
def wite_db_file (data) :
data. to_csv (“Result. csv”, mode= ‘a’ )
def fillna_def (data) :
data = data. fillna ( “ “)
return data
After processing this data, the team passes the control block to the write DB function. But don’t forget: nothing happens after building the pipelining. Specialists have a stack of pending tasks created and saved in the variable batch results. And at this stage of the loop, nothing has been executed. To start execution, they have to run compute. To do this, they create a results variable and call the compute method for the given batch results.
How to Analyze the DASK Dashboard and Metrics
Below you see the screen divided into two parts. The left side is the DASK dashboard. The right side displays system metrics as a resource monitor and has three functions: batch, fillna_def, and write_db. While the loop is running, a status bar appears. This shows that the batch function is running, the result is sent to fillna_def, and the result of this function is already sent to the result of writing to the database.
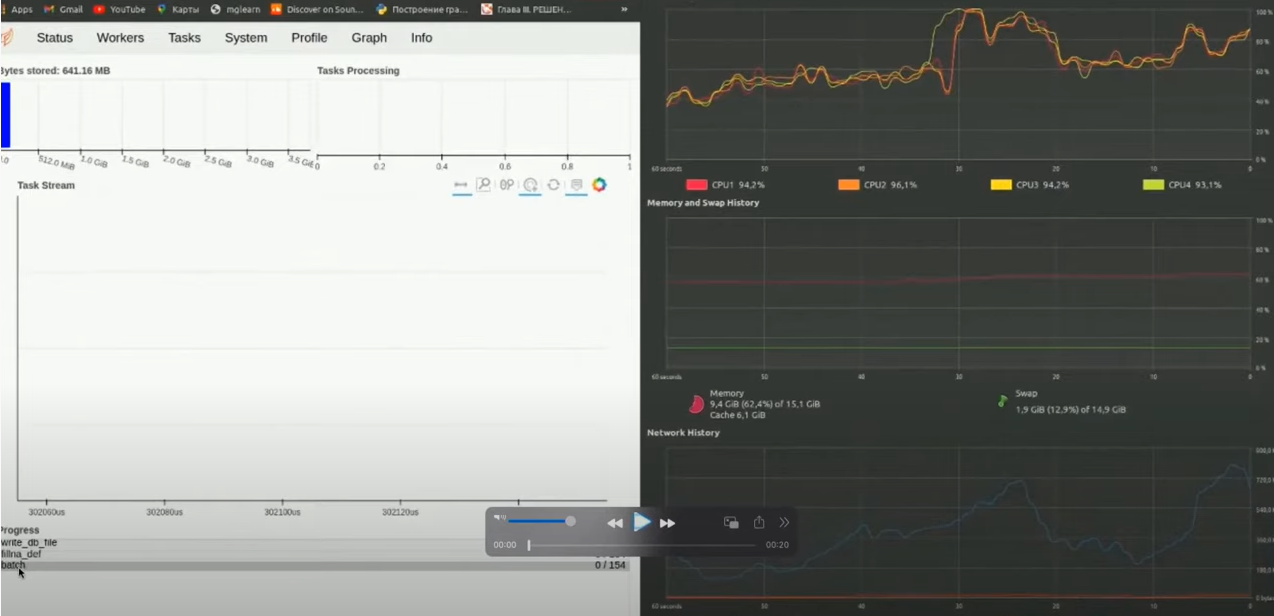
There are four workers involved here. Since the local cluster is nested, all processor cores are used, so you see four directions for data processing.
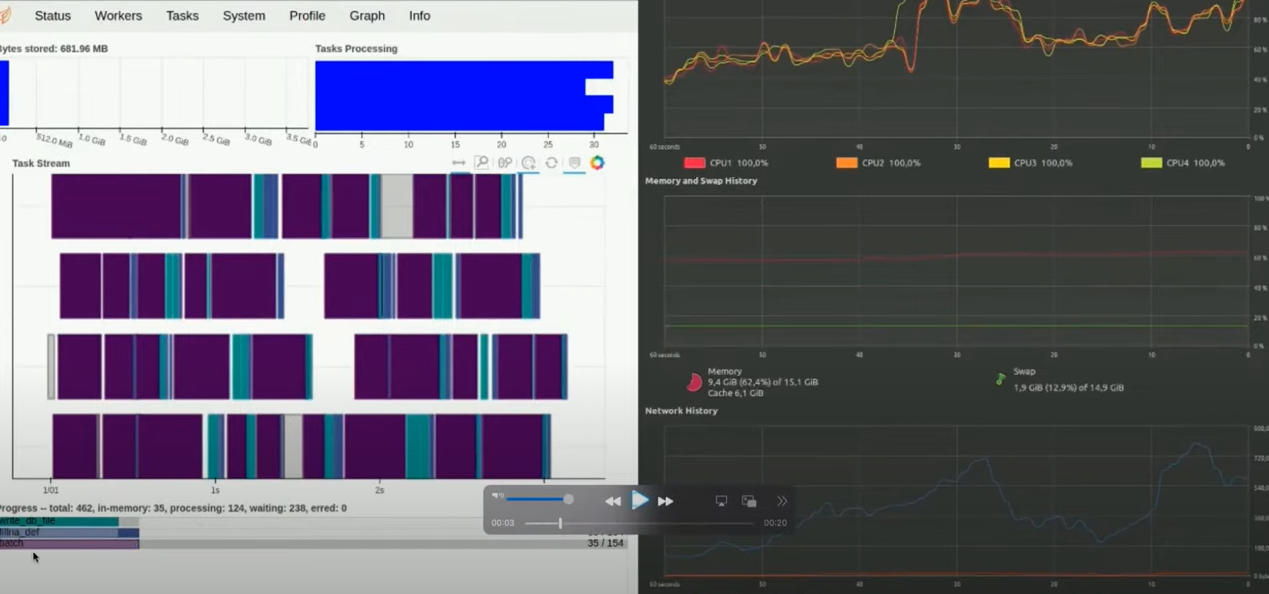
Let’s focus on task processing. It shows how much time and which task takes resources and the total bytes stored (the amount of data written to memory). For example, you took a small part to speed up the process. In reality, it can take hours or even days, depending on the amount of data.
It should be noted that resource monitoring shows that the CPU is under 100% load. The data is well-parallelized between compute instances, which allows it to speed up the work considerably.
Let’s analyze the efficiency of the task on a slightly more significant amount of data. Using a single thread, this process took about 250 seconds, while DASK managed in just under 100 seconds. Multiprocessing was done as an example, but DASK itself is built on the Multiprocessing module. Therefore, the results are more or less similar due to the use of a local cluster. DASK can scale to multiple compute instances in a cluster (say, Azure or Google Cloud). And this can improve performance more significantly.
Best Practices
The examples will only seem simple at first glance. In fact, they can be confusing, and here is why.
For example, let’s look at reading a reasonably large .csv file. On the left, you see a code with an error. This is because it is read firstly in the pandas data frame, then run it in a loop, and there were applied some methods to analyze data from the data frame. But that shouldn’t be done this way. After all, DASK can read data frames independently in parallel mode.
On the right is a block of correct code. Here the data frame proofreading is wrapped essentially in the dask.delayed decorator and read in parallel.

@dask.delayed
def process (a,b) :
a = “Some function logic”
df = pd. read_csv ( “very_big_file_csv”)
results = [ ]
for item in L:
result = process (item, df)
results. append (result)
@dask.delayed
def process (a,b) :
a = “Some function logic”
df = dask.delayed (pd.read_csv) ( “very_big_file_csv”)
results = [ ]
for item in L:
result = process (item, df)
results. append (result)
The following example is reading lots of .csv files. If you have a directory with many .csv files, there is no point in going through them one by one and reading them out in pandas. It’s much easier to run multiple workers at once, handling this task faster. Note the left block. In the loop, it’s necessary to go through the files the same way, read each separately into the pandas data frame, and then convert it into the DASK data frame. But this way, there is more code, and it is generally inefficient.
In the example on the right, there are simply specified filenames (the directory name of the files) and used the DASK method of datagram read_csv. In this way, all the data in the parallel thread should be considered.

df = ddf. DataFrame ()
for fn in filenames :
df = pd. read_csv (fn)
ddf = ddf. append(df)
df = ddf. read.csv (filenames)
The last example is about avoiding instant computation. An important nuance: even if you use the keyword compute, it doesn’t necessarily mean that you are doing it right. The example on the left looks like computing the .csv file using the DASK data frame. However, when some operations to execute are set up (in this case, finding the minimum and maximum values in the x field), immediately call the compute keyword on the second line. This forces DASK to switch to instantaneous computation. It turns out that the search for the requested values is performed sequentially: first, the minima, and only then, the maxima. These are essentially single threads. To do multithreading for DASK, you need to wrap everything in a compute function and set the calculations inside it, which is implemented in the code on the right.

df = ddf.read_csv( “some_file.csv”) xmin = df.x.min (). compute () xmax = df.x. max.compute ()
df = ddf.read_csv( “some_file.csv” ) xmin, xmax = dask. compute (df.x.min () , df.x. max.compute () )
DASK is a handy framework that will appeal to the dataset designer who has ever worked with pandas. Even if you are unfamiliar with it, the detailed documentation of DASK will allow you to master it quickly. The framework features listed in the article make DASK an excellent additional tool for almost any data scientist.