The famous physicist Niels Bohr said: “Problems are more important than solutions. The latter may become obsolete, but problems remain.” And it is true, especially when it comes to modeling and organizing data in applications. This problem still exists.
On one hand, relational databases are not ideal for today’s infinitely scalable world. On the other hand, new NoSQL models also have disadvantages, at least with data duplication. Therefore, almost every developer is looking for the best way to organize a database. Sometimes this task can be solved by combining relational and non-relational schemes.
This article will explain, with examples, how to apply NoSQL approaches in relational databases and when it is appropriate. Many theoretical points won’t be focused on in the hope that experienced readers understand what is being discussed.
Relational Database Features
Most developers are well aware of the concept of relational databases and use it in almost every project. The founder of this model was Edgar Coddu. In 1970, he published the paper “A Relational Model of Data for Large Shared Data Banks”, where he first described a concept built on relational algebra. At that time, frankly speaking, his idea was not completely understood. Therefore, Edgar later published “12 rules of Codd” for a more detailed formalization of his theory.
What makes a relational database exactly relational?
- Database scheme. It includes a set of tables, their attributes, and the relationships between them. Also, here are Primary Key, Foreign Key, etc. It is important to know this scheme in advance because without this information it is impossible to put any data in the database.
- Normal forms. If the database is made as one huge table with all the data, it will work very badly. The data should be divided into smaller tables creating connections between them. This is what normal forms are for. Relational databases are built on them.
- ACID transactions. It can be said that this is the most important thing in the described type of databases. The name ACID comes from Atomicity, Consistency, Isolation, and Durability. In a relational database system, there is a transactional mechanism, as a result of which a set of queries or a set of operations from the database will save all this data after completion. At the same time, only then all these data will be agreed with each other, and access to them will be available even if the entire system crashes.
These principles help to organize the work with databases quite well, to make it simpler and more understandable. This is why relational databases are so popular.
Problems with relational databases
However, over time, questions began to appear about such databases. Object-relational impedance mismatch became the first inconvenience that caused developers to look for an alternative. It is worth explaining this term with an example.
Imagine that there is a User class with its own fields, and in it, there is a collection of posts that he, a real user, liked. However, if a database scheme is built and this data is placed according to the described rules, it will be stored in a slightly different or completely different format than is in memory. Because of this, developers have to invent mechanisms for obtaining a snapshot of data, write a query with a join, know the relationship between the tables, and return the correspondence after receiving — and all this causes a lot of trouble.
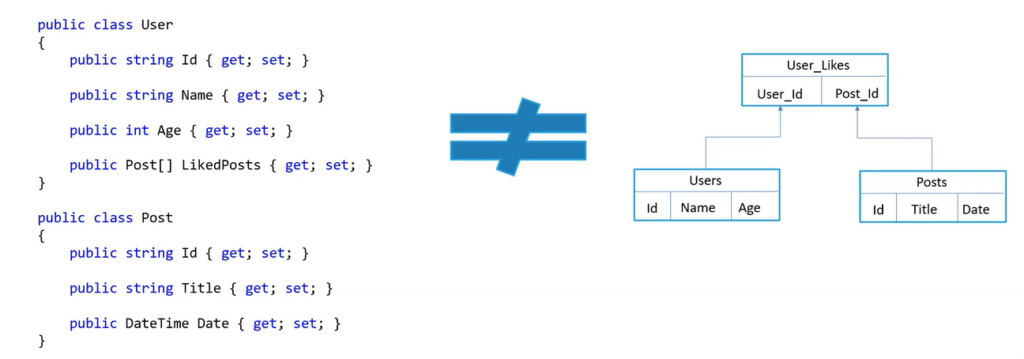
To overcome this problem, there were attempts to create object-oriented databases. But the idea did not catch on, because these were the same relational databases with a built-in mapping mechanism. The real problems began with reaching new scales: when high-speed Internet appeared in almost every home, and large businesses began operating worldwide. That’s when the developers thought about horizontal scaling, where the system is scaled up by merely adding instances. The idea is simple: one request should be processed by one node. The more nodes, the more requests can be executed. However, this is not the case with relational databases.
For example, there are Users and Posts in the database. If the database is scaled, certain issues may arise. First, users can be on different nodes. Secondly, posts for a user on one node may end up on another. Because of this, to execute a request, for example, select from users joins post, it is necessary to visit two nodes. In addition, the data may be unevenly distributed. As a result, the speed of data processing drops, and the system becomes too complex. That is why another alternative was needed.
What is NoSQL?
As is often the case, the first successes in creating a new type of database were achieved by large companies — Google and Amazon. They were one of the first to decide to move away from relationality and find a new paradigm. During 2006-2007, papers appeared about their cloud databases — Big Table from Google and Dynamo from Amazon. The ideas expressed in these publications were not linked to relational theory. There were no plates, connections, or joins, and most importantly, the developers of these systems achieved real scaling.
This experience inspired many programmers to develop similar ideas. So, in 2009, several developers organized a meeting on this topic. Serious brands joined the event, including MongoDB, CouchDB, and others. The initiators of the event were not looking for a slogan for it, but for something like a hashtag to attract the attention of the community on Twitter. This is how the name NoSQL was born.
There are several main models, and each has its own characteristics, advantages, and disadvantages. Therefore, it is worth telling a little about each of them.
Key-Value Store
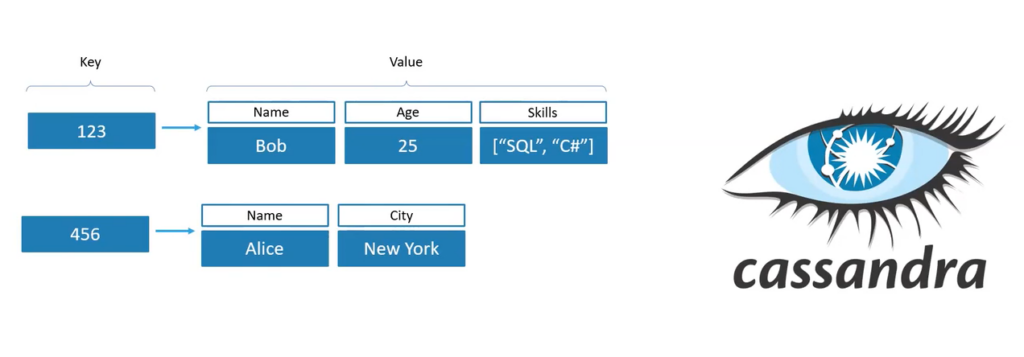
This is the simplest NoSQL paradigm. The key and value are stored in the repository — that’s all. There are no complex fields, or key-value relationships, nothing at all. The main advantage is that such a structure is infinitely scalable. Its most vivid example is Redis, which is used by many as a cache.

Column Family
This model has taken key-value and pushed it further. There is also a key here, but the value is no longer a simple string, but a set of its own key-value pairs. It means it is already a system of columns with a value, where each row can have its own sets. An example of such a database is Cassandra.
Graph Databases
This option is a little exotic and is based on the concept of graphs. According to the idea, the relationship between data is also certain data. The construction of such data connections will resemble a graph. In such a way, it is possible to get a wide range of opportunities for creating hierarchies or entangled connections. This is actually how all social networks work. One user is connected to another as a friend, the latter in turn is subscribed to some group, and the first one likes some posts — and these are all examples of connections that are data. Neo4j is built on this model. It even has a very interesting syntax for writing queries to such an unusual database.
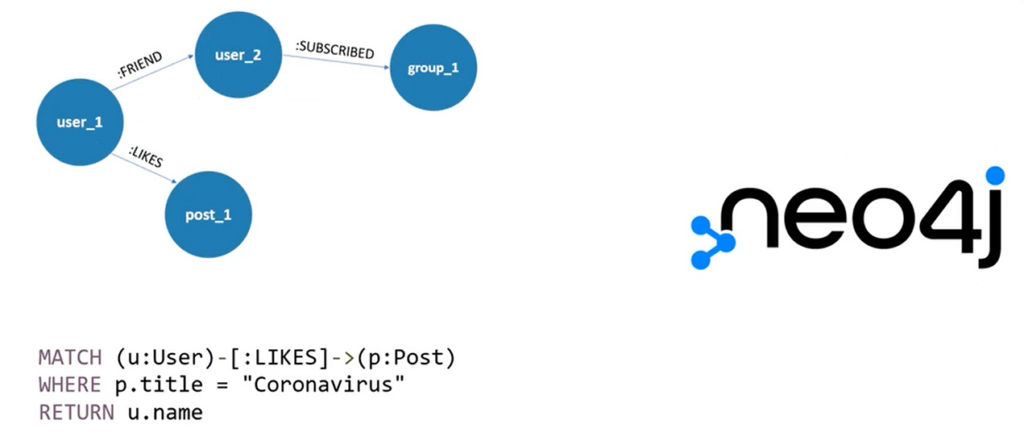
Document Databases
Many developers associate NoSQL primarily with Document Databases. Their principle is as follows: an entire document is stored according to some key in the form of a set of key values of infinite nesting and the most unexpected structure that can be needed. One of the popular examples of the implementation of this paradigm is MongoDB.

MongoDB in practice
It is worth telling about MongoDB in more detail. If a project in which Google Forms with simple features has to be constructed, the user can create a form with a free set of fields, any number.
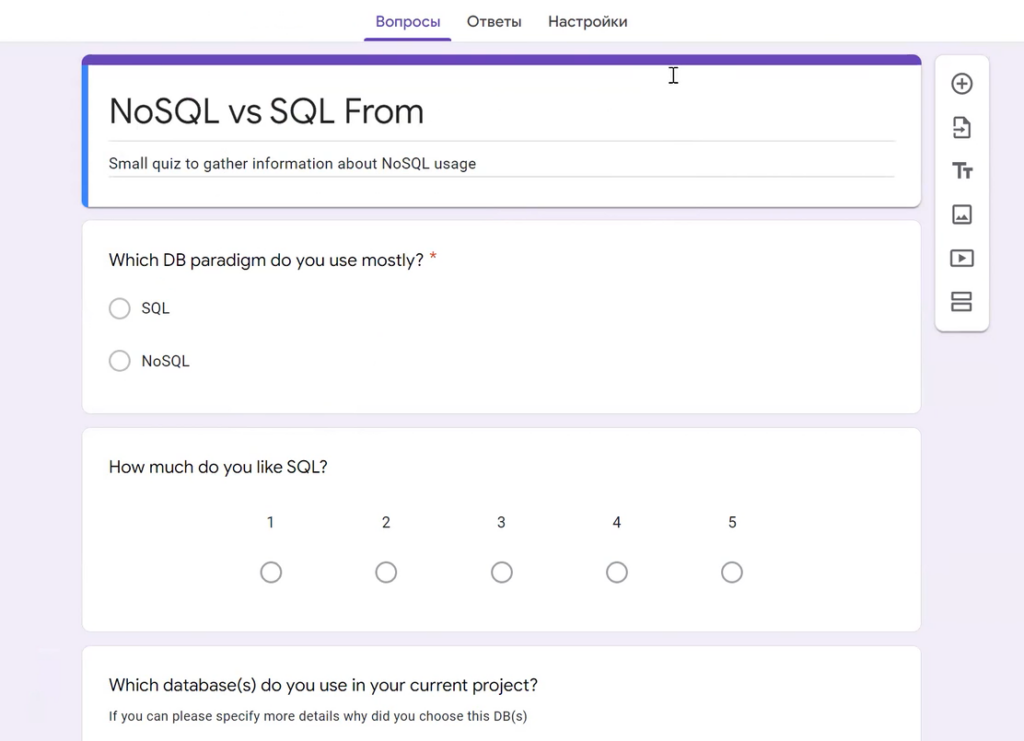
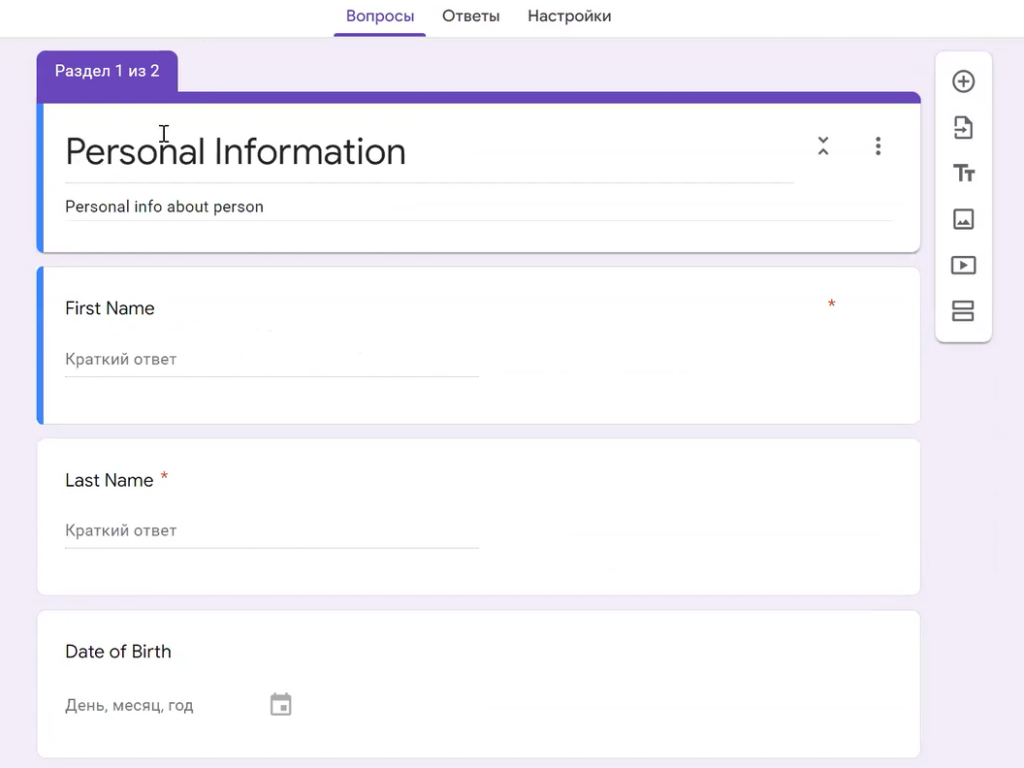
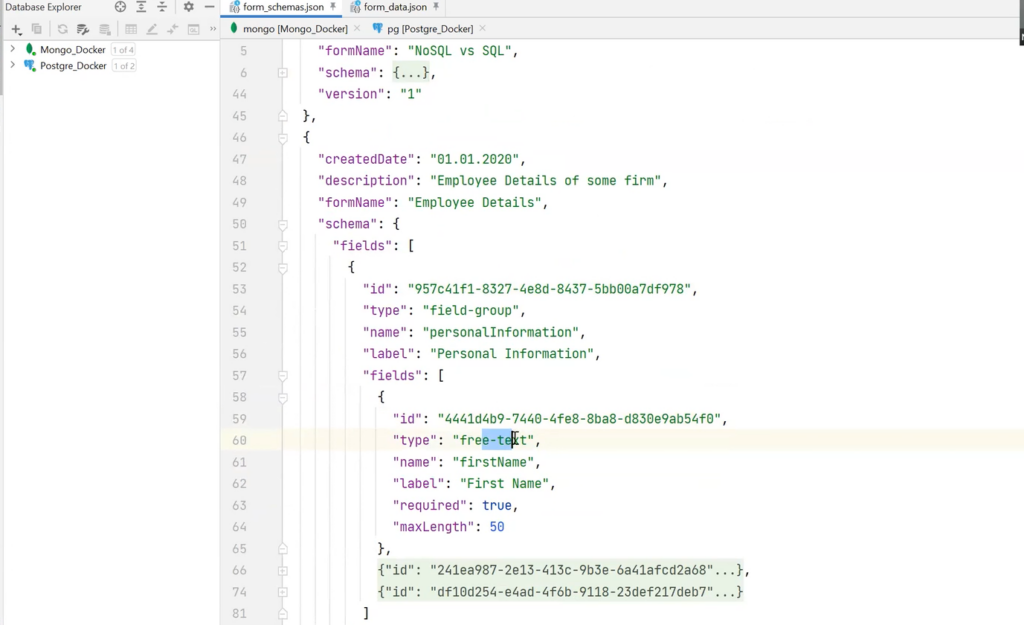
The “NoSQL vs SQL” form is simple: fields with a radio button, a scale, and free text. However, the user can create a complex form. For example, with Personal Information or Employee Details, where there are tabs: full name, date of birth, work experience, technologies, etc.
If it were necessary to solve this problem in the relational paradigm, it would be very difficult to create a DB schema. After all, it is unknown how many fields there will be, which fields will be created in the future, how their functionality will be expanded, etc. This is where MongoDB comes in handy.
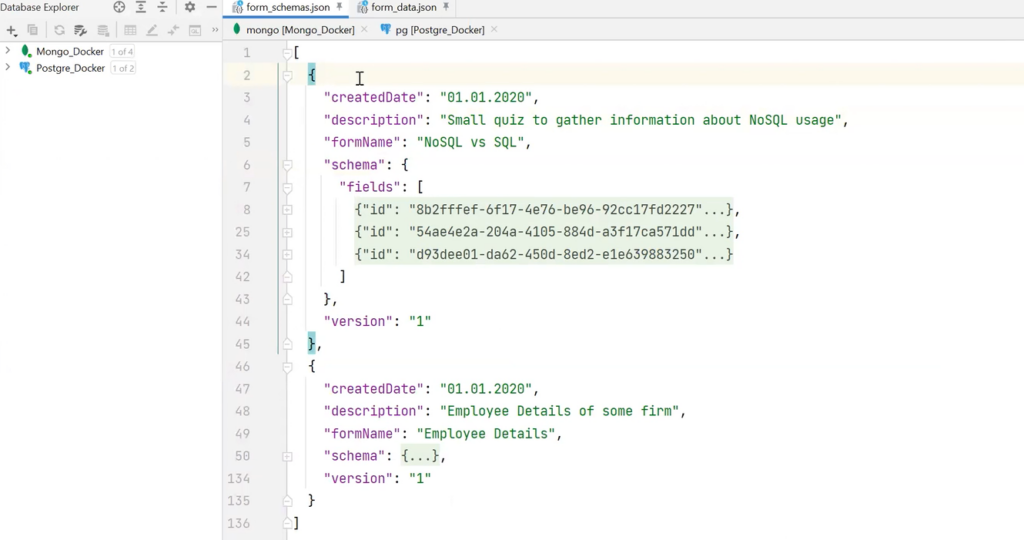
To solve the problem, a form schema, that describes the structure and possible data, can be created. For example, there are service fields in the form schema: createdDate, description, and name of the form. The schema will contain a set of fields that it describes. For instance, there is a single choice field with name and options fields. And the latter is an array of objects. There is also a range field with min and max labels, a simple number, and a free-text field with some kind of hint.
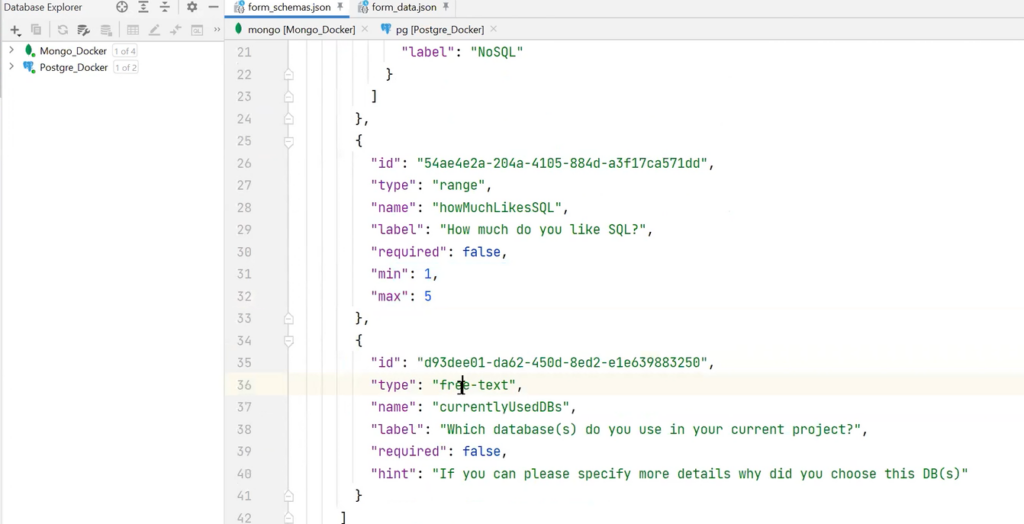
In case of need for a less complicated form of Employee Details, it is possible to create a field type with the name field-group, which will have its own fields — it will be a kind of recursive structure. There can be free text, number, and date — and the same with the second tab.
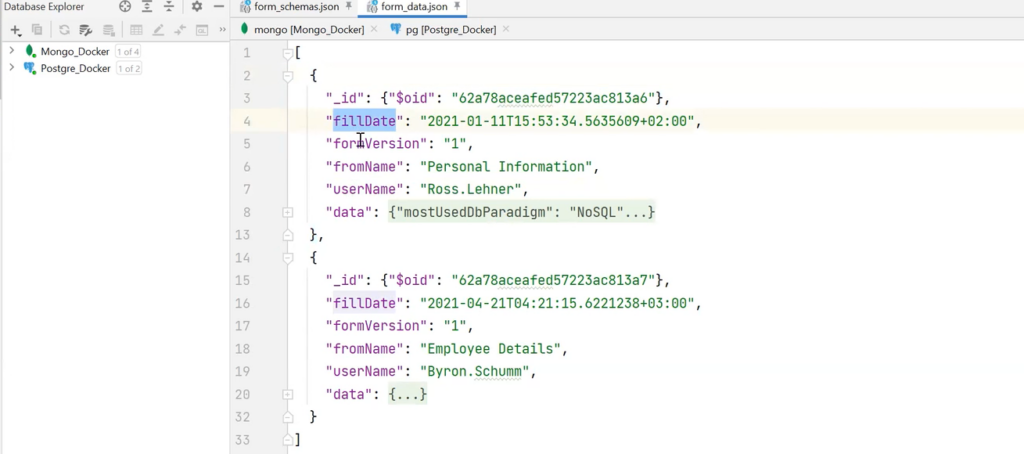
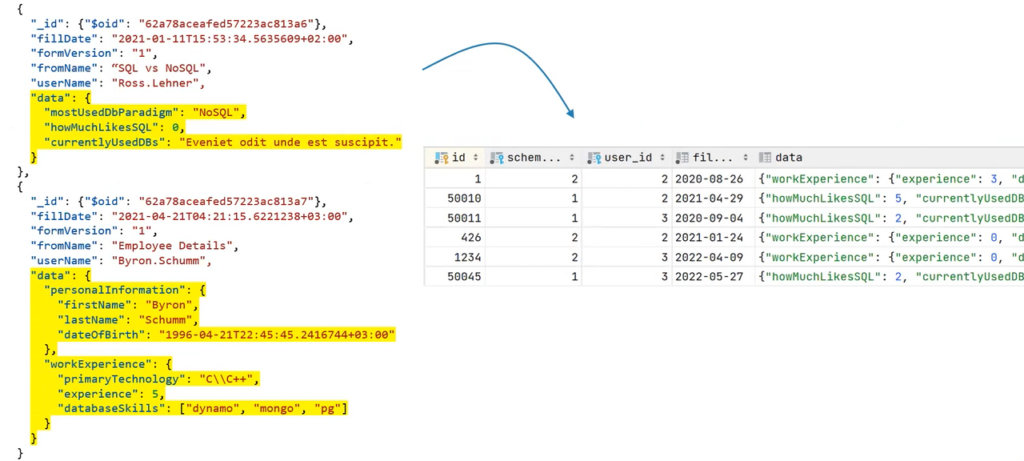
Ideally, all of this should be stored in JSON and the responses in another format. For example, there is fillDate, information about what has already been filled, and the data field, where all the required data is added according to the described scheme.
How to implement this in MongoDB? This database has such a concept as collections. If compared to the relational world, these are tables, but with one very important difference. Anything can be in the collection. For example, it is possible to create form_schemas and form_data collections for one and two JSON files, respectively.
Also, using the API and Query syntax in Mongo, there is an opportunity to search for all available form_schema and get a list of documents. In this concrete case, there are two of them. These are the same form_schema defined above.
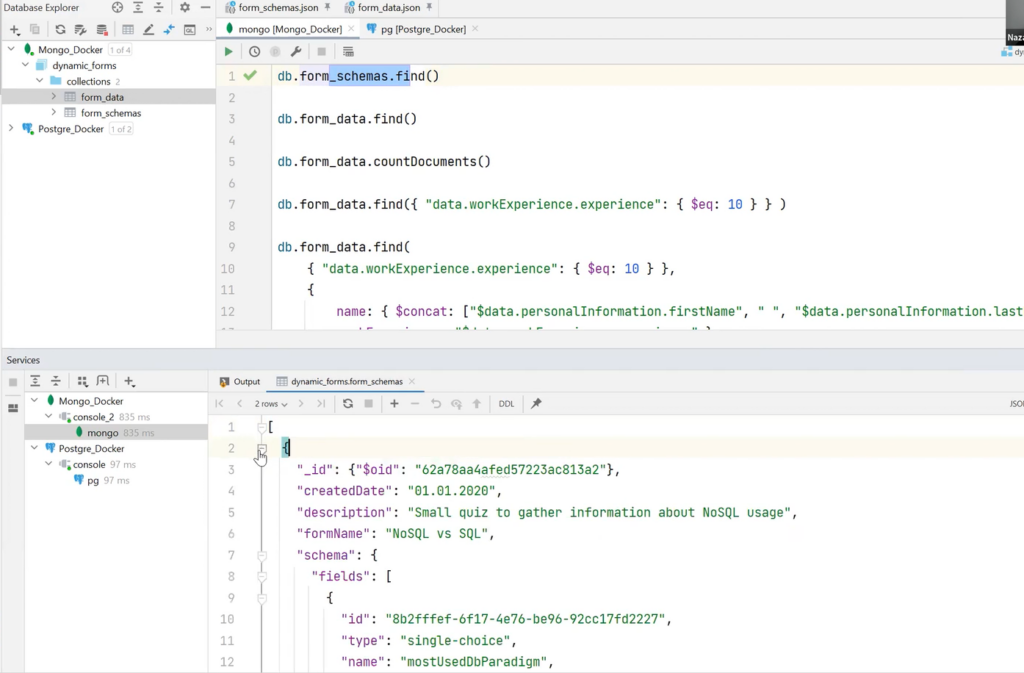
It is also possible to get all the form_data and documents that belong to this collection.
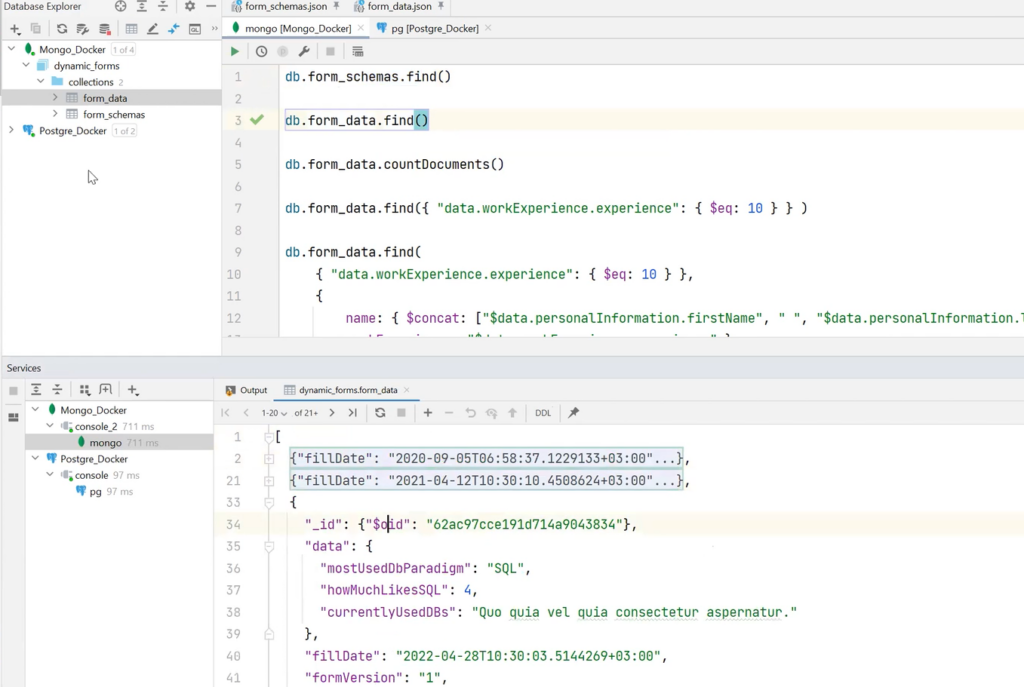
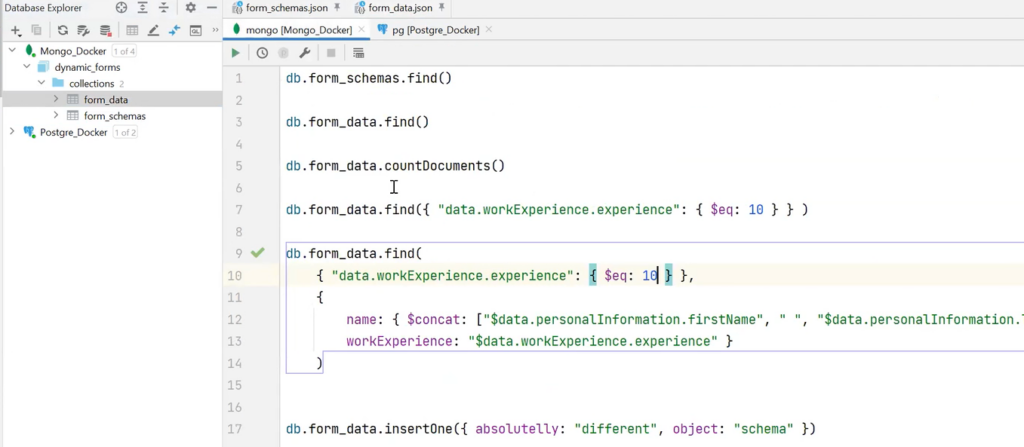
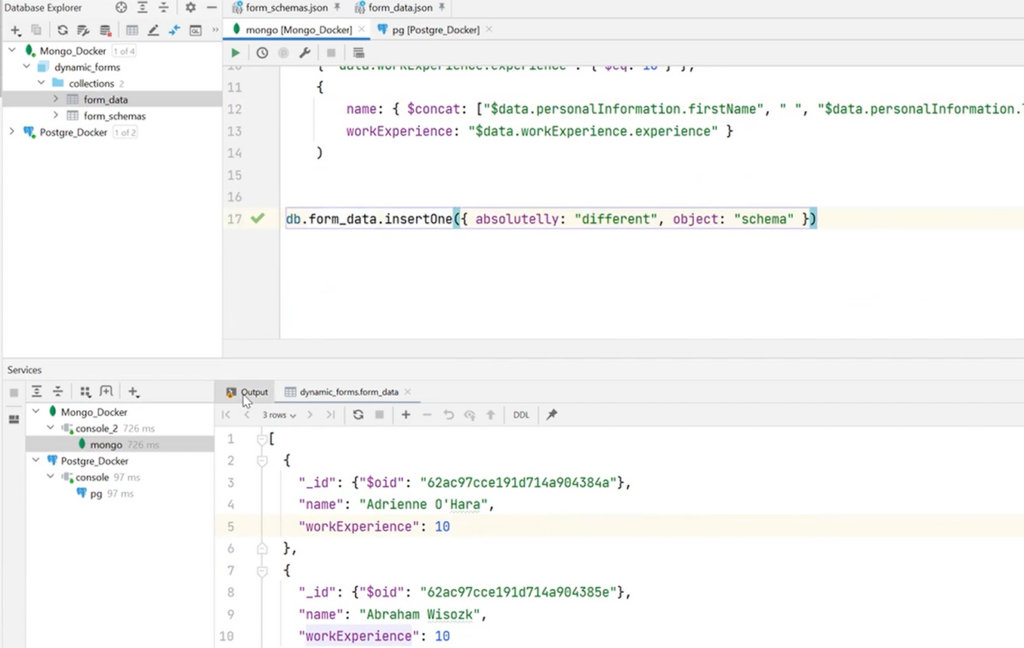
In addition, queries can be created. For example, it is necessary to select a specific form_data — only those data where workExperience is 10 years. Using MongoDB’s special syntax and tools, people with 10 years of experience can be found.
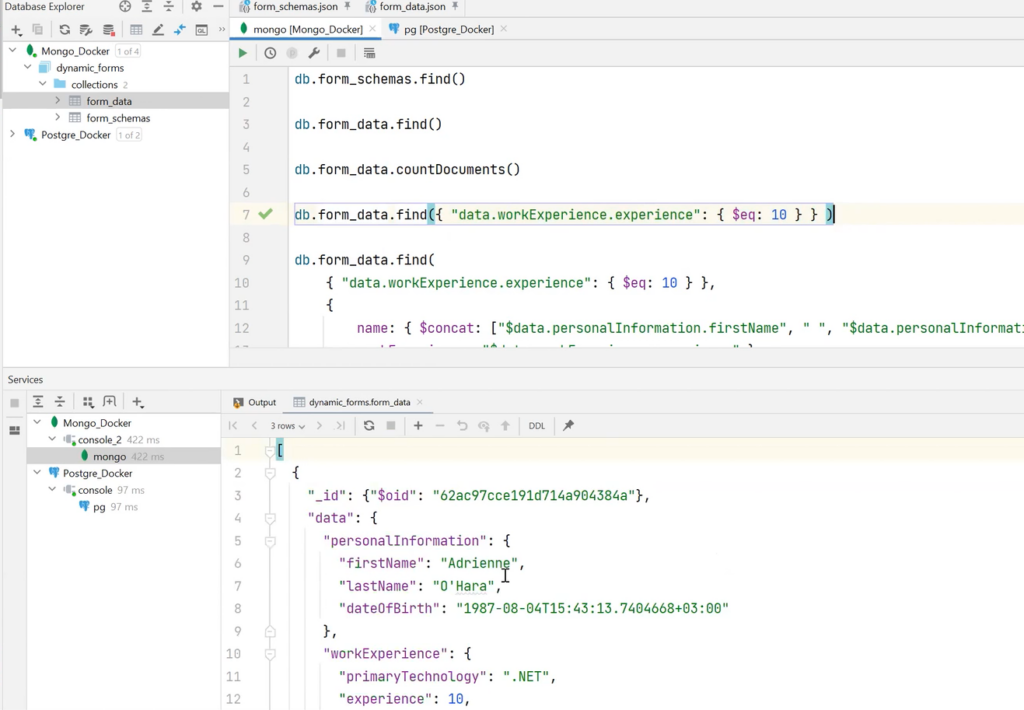
If these fields are not needed, it is possible to expand the query and select the required fields. For example, name and workExperience.
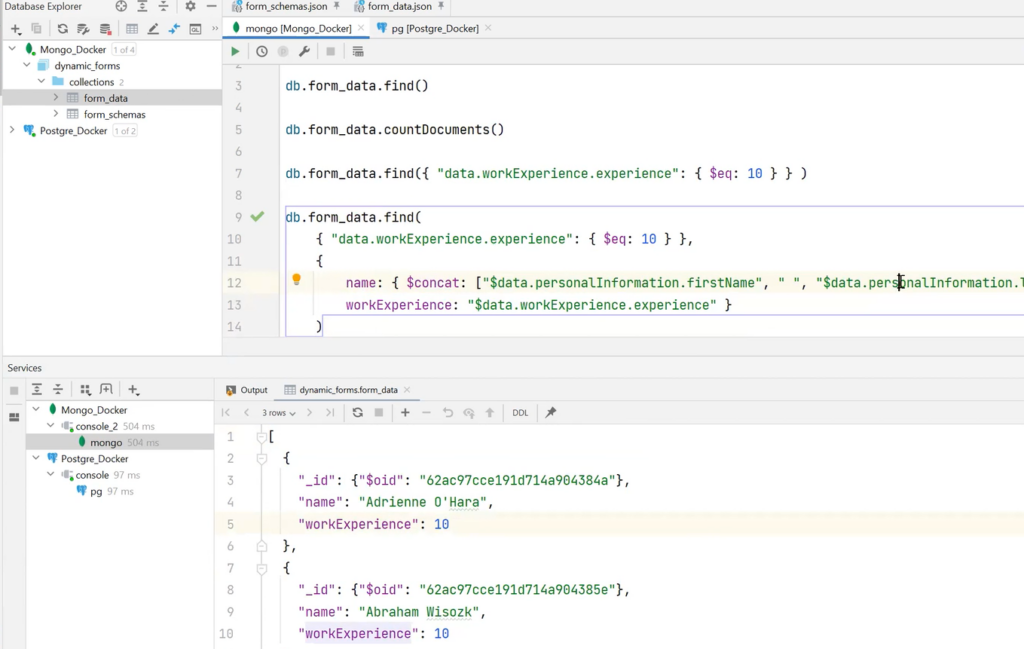
It is important to remember that collections are schemaless. There is no need to insert data that fit the schema. It can be random. The object in the illustration below is a good example. Such a request is executed without problems:
Advantages and disadvantages of NoSQL
Like any other solution, non-relational databases have positive and negative features. Having summarized the various NoSQL models, such advantages can be highlighted:
- Scaling. Usually, it is done by PartitionKey. This is a piece of data that is known to lie in one place. This is the point of horizontal scaling. If the data is put in advance, because the PartitionKey is known, the scaling will be almost limitless.
- Eliminating Object-relational impedance mismatch. Using examples from MongoDB, it was shown that data can have the desired schema and structure. For this, there is no need to write complex joins or model the data in a way it is not used.
- Schemaless. Objects of any shape can be inserted into one collection. Although, of course, this can also be a disadvantage of NoSQL.
The main disadvantages of non-relational databases are:
- Partial transaction support. Different NoSQL paradigms and individual databases partially support ACID concepts, but generally, they aren’t there, because they were sacrificed to scale the system.
- Rejection of relationality. If there are no joins, then there is… duplication of data. Here it is important to understand: this is the norm for such a system — not a bug, but a feature, as they say. Therefore, it is necessary to model the data in a way that such a system is as effective as it is realistic.
- Limited search capabilities based on complex criteria. NoSQL has “find”, which was mentioned in the example. However, there are problems with the global scaling concept. If the data is located on a large number of nodes, then to search by a certain criterion without Partition, it is necessary to bypass literally all nodes. This effectively nullifies scaling per se.
As for the concepts of non-relational databases, it is worth considering where this or that database will be used. After all, what is good for one developer is not always good for another. This demonstrates the use of NoSQL models by certain companies. For instance, Redis, a standard for file load systems, is based on the Key-Value Store. Column Based is found in Facebook, Instagram, and Netflix products — for predictions, machine learning enhancements, and content filtering. The eBay catalog is built on Graph Databases. Document Databases are the most common type of NoSQL databases. Any data structure and CMS can be modeled with it.
Using JSON in relational databases
Due to their scaling capabilities, non-relational databases are quite popular, but they cannot be a perfect solution. At one time, the developers thought: is it possible to use the developments from the NoSQL world and solve the problem precisely in a relational form?
In the following example, there is real data in the data field, which is filled by the user, and the form scheme in a specific document, as well as duplicate data: _id, fillDate, formVersion, fromName. It seems as if the data can exist in the form of an ordinary table in SQL because their quantity and quality are the same. But then what to do with the strange data field?
The first thing that comes to mind is to make the data column in SQL NVARCHAR(MAX). It’s basically a string, and it is possible to place anything there. However, the Application Layer would need to validate that it is JSON. If a search is required, this causes some problems. Therefore, today most databases provide a special data type or tools that help manipulate JSON in the database itself.
PostgreSQL, where this type of data is called jsonb, might be a good example. It is binary and supports the same operations on itself as JSON: format validation, flexible search tools for nested fields, and the ability to create an index. It is worth considering its possibilities in practice.
PostgreSQL has three tables: users, form_schemas, and form_data. This is the same structure as in MongoDB. In fact, form_schemas is the definition of the form, and form_data is the data filled in by the user.
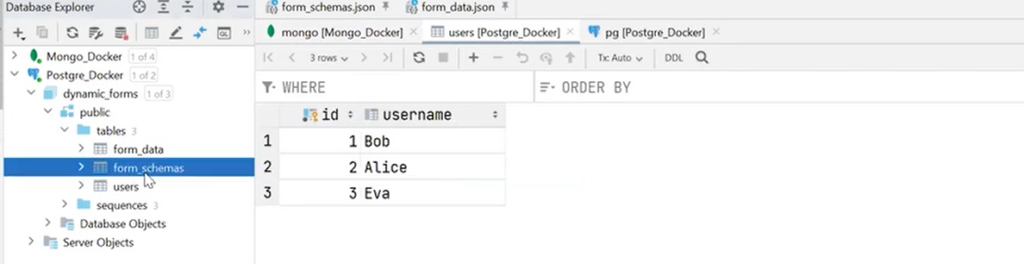
It is also noticeable that in form_schemas the common fields are divided into their own columns, and the schema is already JSON.
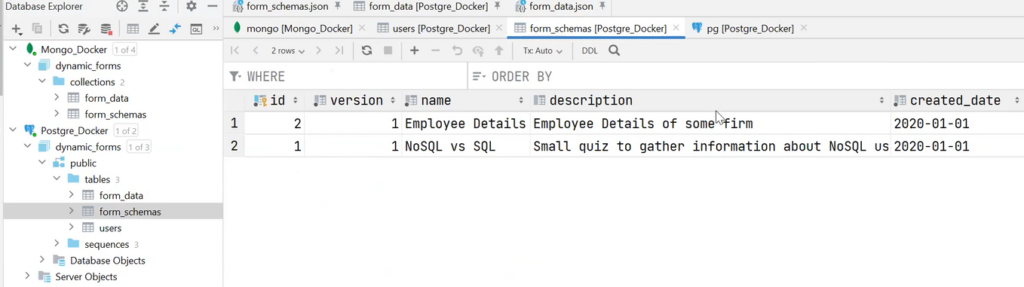
The same can be said about form_data.
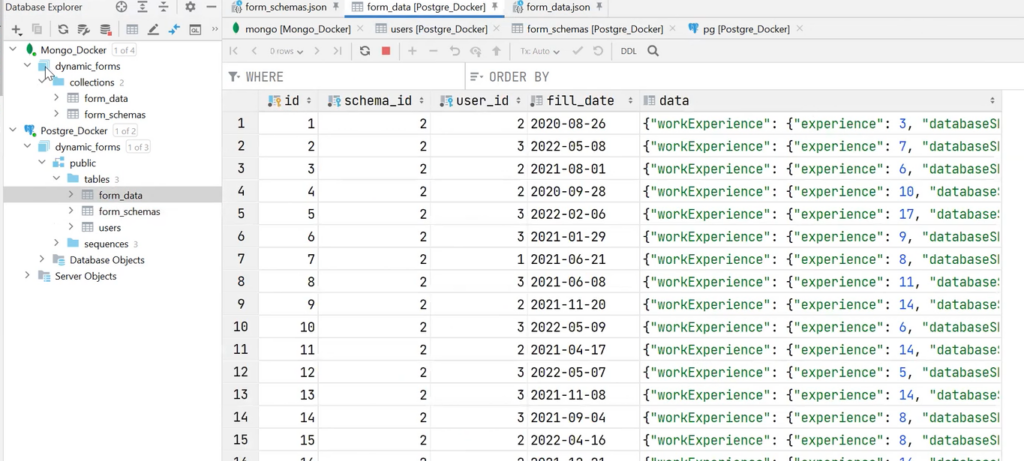
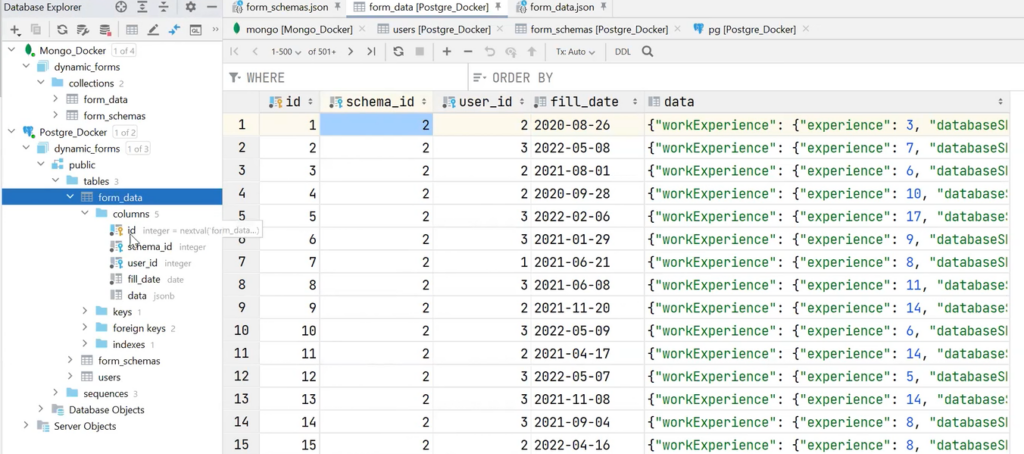
It is worth paying attention to the fact that there are separate fields and connections here — valid foreign keys. For example, after opening the definition of the table, there is data (the same jsonb), and in foreign keys, there are schema_id (it indicates which schema jsonb belongs to) and user_id (indicates the user who filled in the table). This all ensures data consistency.
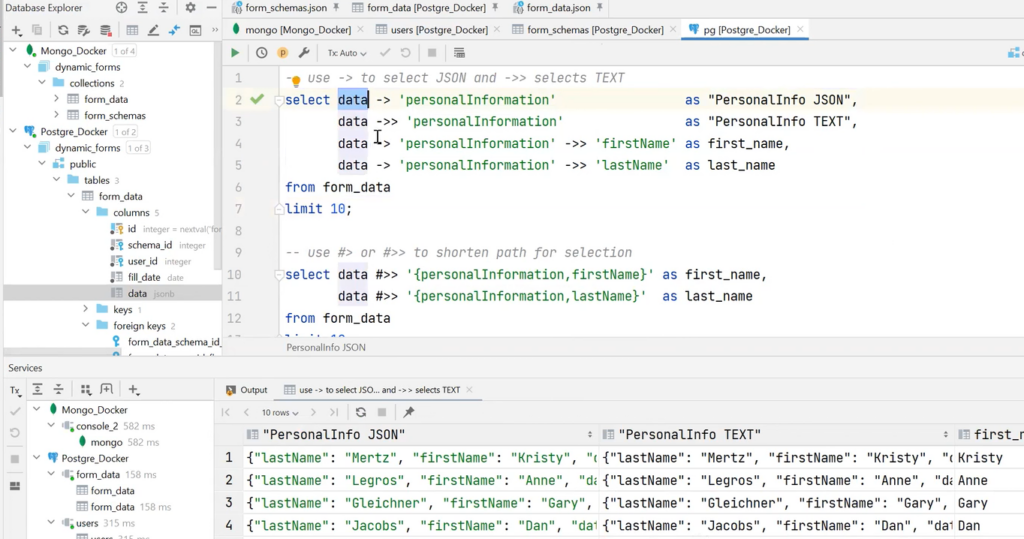
It also provides tools for manipulating the date. First of all, it is worth understanding what can be extracted from JSON. The special syntax with the arrow -> can be used to refer to the fields of any nesting. The difference between single and double arrows is that two — act as a terminal operation. That is, we make select as text, and this is such a string.
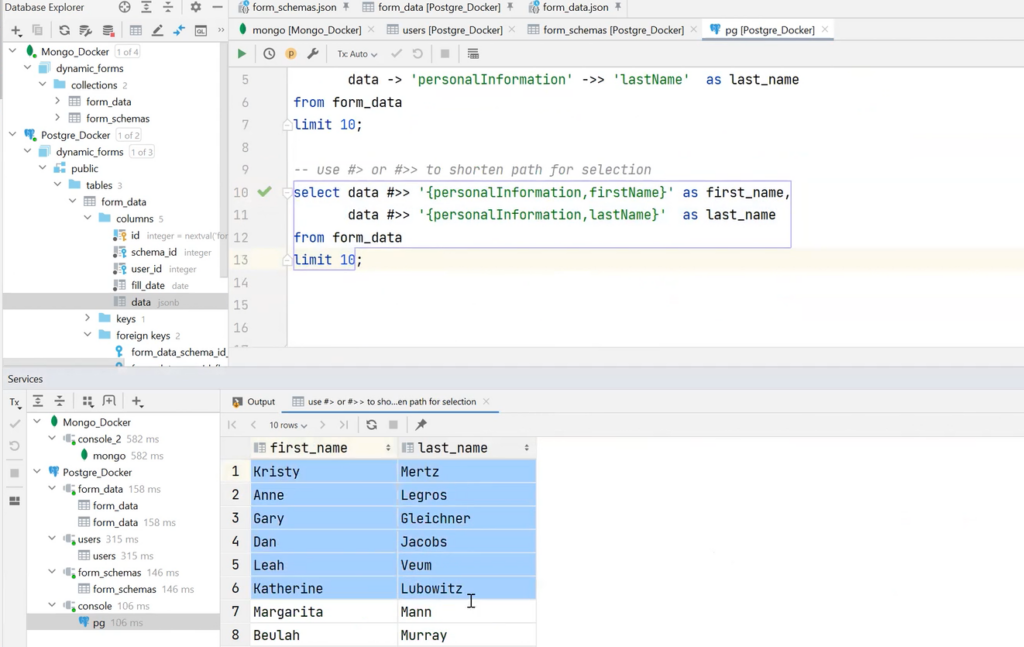
A shorter syntax can also be used. For example, to get to personalInformation firstName, make it short and get the data from that data field. In addition, it happens very quickly, although there are 100k requests here:
It is also possible to use this expression not only in select but also in where. For example, there is a need to select users with workExperience of more than 10 years. Since it returns text, it should be converted to a number, but it will end up getting all users with more than 10 years of experience.
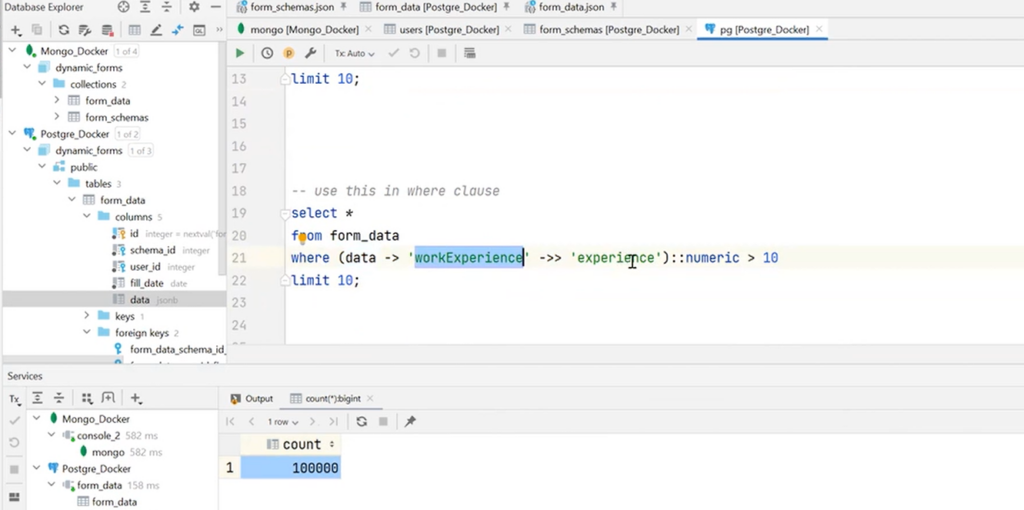
Next, it is necessary to talk about a rather interesting operator, which can define contains in the data itself, in JSON. For instance, there is workExperience and databaseSkills, with knowledge of specific databases.
So, there is an opportunity to write a query that will show all users who know PostgreSQL. This is very appropriate when searching for information on an array.
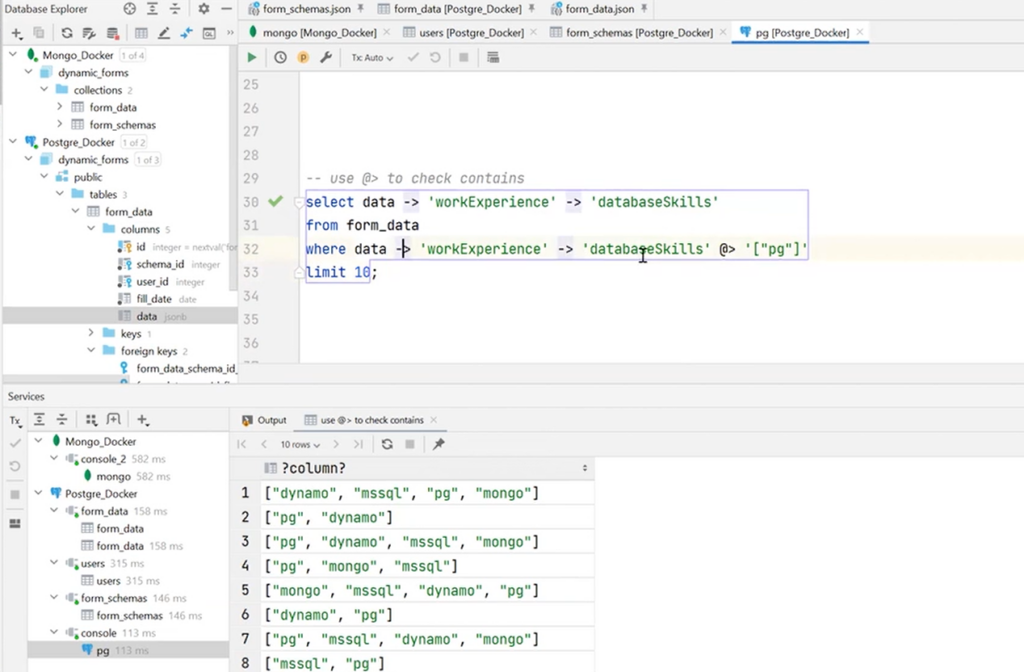
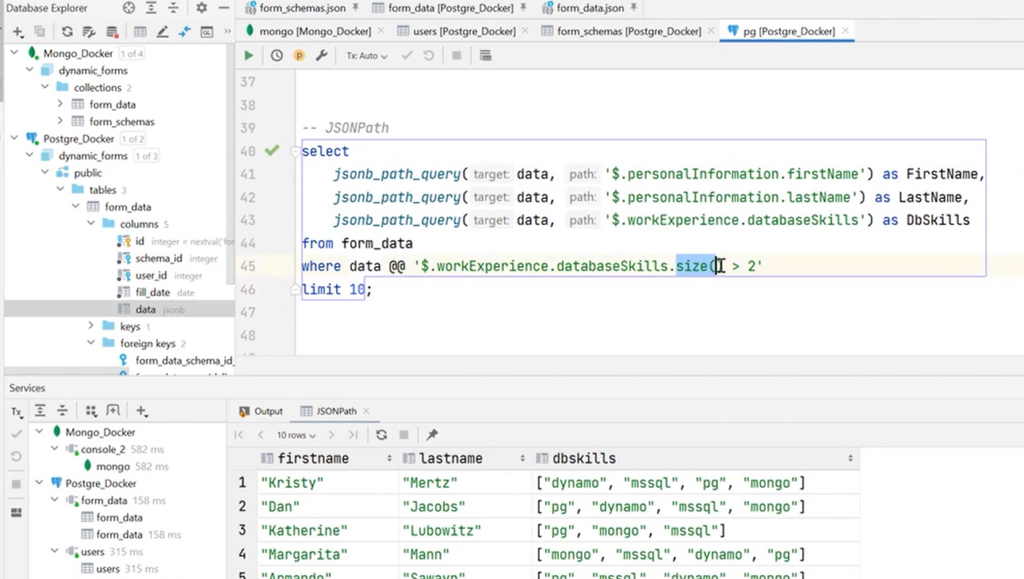
Also, JSONPath should be mentioned here. It is a JSON query language similar to XML’s equivalent XMLPath concept. There’s a string here where $ is a root. Next, we a request to fields in JSON is made. For example, there is a need to select firstName, lastName, databaseSkills for those users who have more than two skills in databaseSkills. If values are not selected with arrows, it is possible to refer to the syntax and enter the @@ operator to use where. And all because jsonb_path_query are our functions:
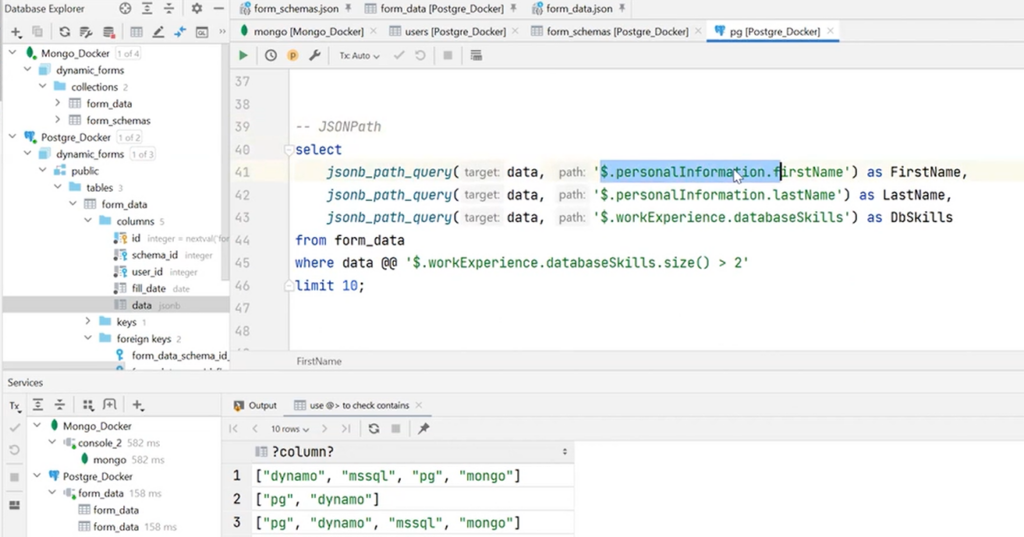
It is seen here that there is a size function inside the string. It is built into the JSONPath specification and can output the number of elements in an array. For this, the operator >, greater than some number, is added. In this case, it is 2. As a result, it was thanks to this that PostgreSQL processed this string, understood its tasks, and extracted the necessary data.
Finally, there are indexes. They can be created on data inside JSON to process requests to such a file faster. For example, an index on workExperience was added and there is a need to find all users in whom this parameter is 10 years. It’s pretty simple, but it should be emphasized that the index is created on a string, not a number. Otherwise, the index will not be processed at all. This is well reflected in the execution plan. The illustration below shows that Seq Scan was used in PostgreSQL to search for users. It took just over 129 milliseconds:
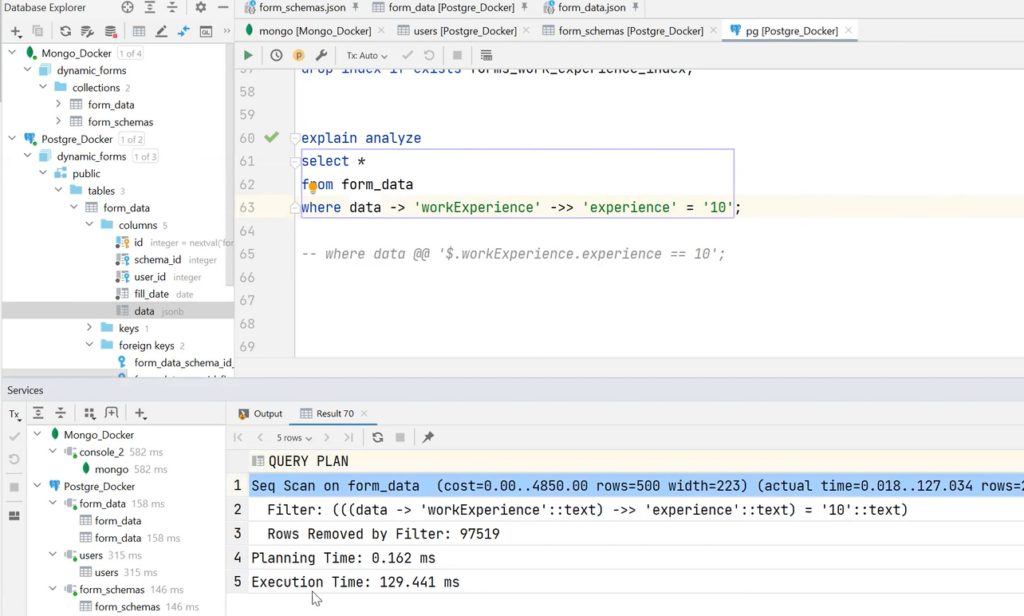
If an index is added for the same query execution, everything will go through as a Bitmap Heap Scan — and the data will be retrieved in 9 milliseconds. More than 10 times faster speed!
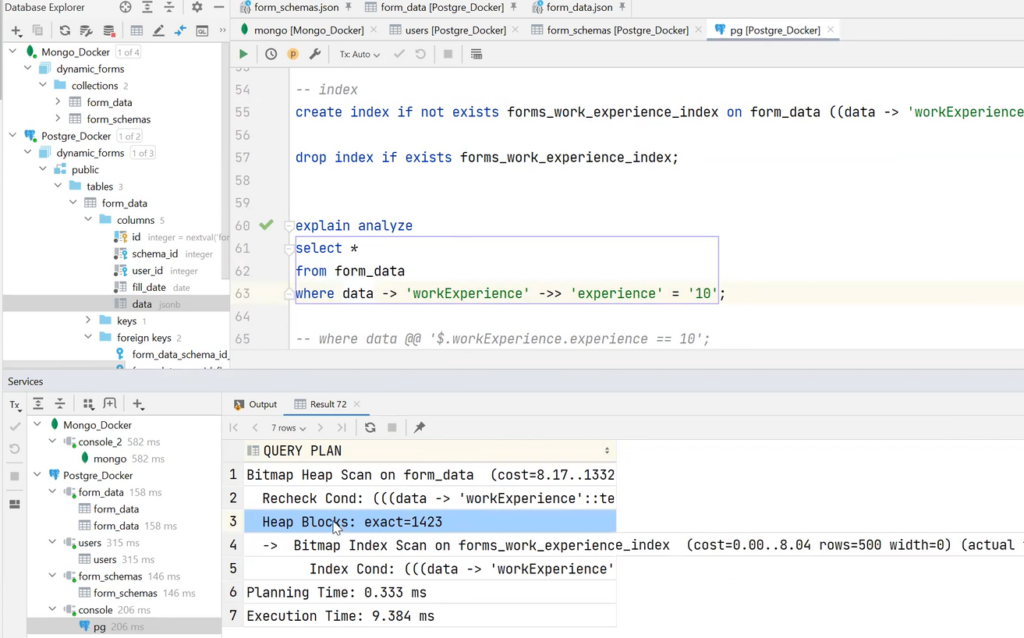
Too bad it doesn’t work with nice JSONPath syntax. With it, the request will come through the Seq Scan in 78 milliseconds. So, there is an improvement, but not so significant.
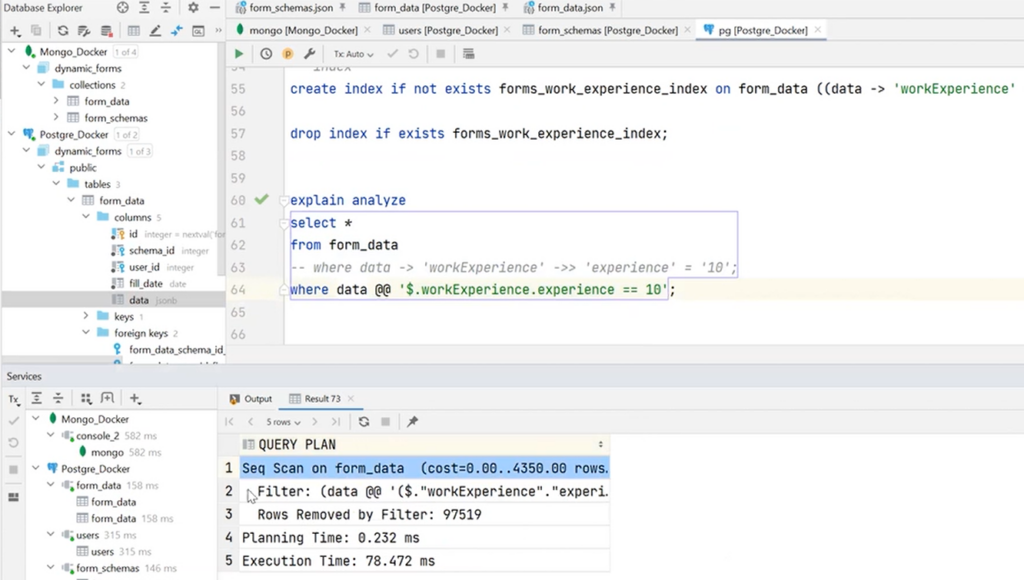
For the index to work on such an expression, another type should be created — for the entire JSON field. In PostgreSQL, this is the gin index. The specified expressions work as Full-Text Search. When they are executed, the Bitmap Heap Scan is launched, and the time consumption will be only 21 milliseconds:
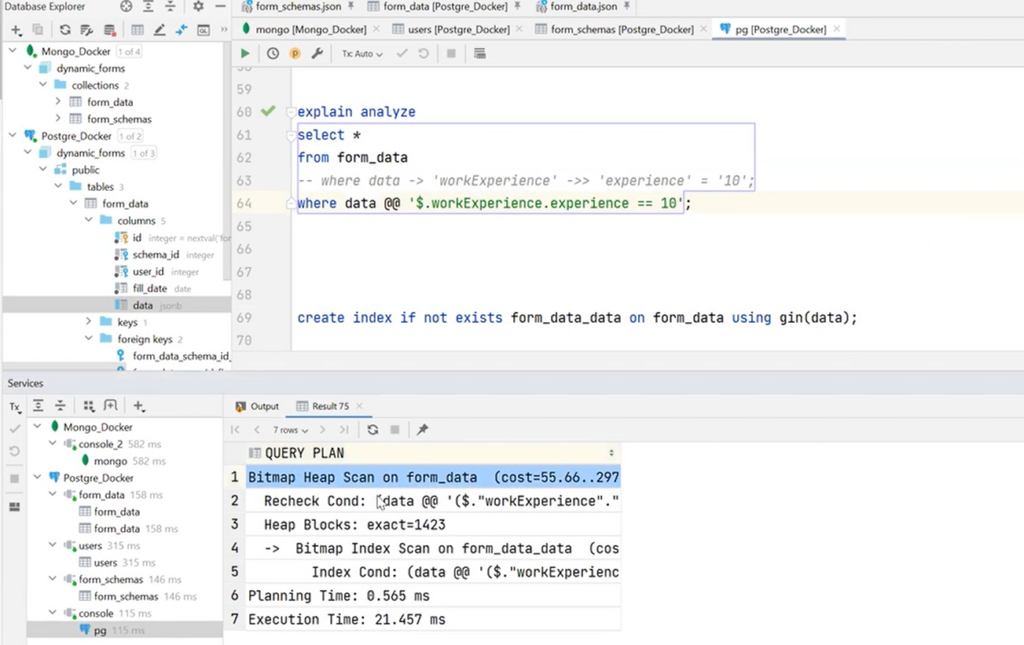
Although this was all demonstrated using PostgreSQL as an example, all major database vendors support this approach in one way or another. After all, they see demand from developers for JSON adaptation in some cases. For example, the code below shows the MsSQL syntax. There are also OPENJSON and JSON_QUERY functions using JSONPath. Similar solutions are available in MicrosoftSQL and Oracle.

Advantages and disadvantages of JSON in relational databases
The NoSQL approach to relational databases has useful properties, including:
- Good old SQL. There is no need to deviate from the accustomed and liked principles and methods.
- “Compatibility” with the relational model. there is the possibility to make joins and selects, to use internal JSON fields in Query where.
- More tools for data modeling. The new approach allows taking the best of SQL and NoSQL.
As for the disadvantages of using JSON in the described manner, they are the following:
- Decreased efficiency in some cases. Using a data type like jsonb and adding an index requires more resources. A NoSQL database like MongoDB will be more productive for such a task.
- No scaling is added. The main advantage of the NoSQL world does not fit into the new model — the relational paradigm is not abandoned. However, now there is an opportunity to do a little more in it.
Summing up, it should be said that the use of JSON in the relational model will be justified in several cases:
- Existing projects on SQL. If a feature that requires dynamic data appears in an application with a relational database, NoSQL methods will definitely come in handy.
- Dynamic constructors of anything with scaling in mind. When it is not known what objects the user will operate and what connections there will be between them, it is worth trying the described principles. As a rule, these are the same forms, workflows, and other things that the user can create with the help of the used tool.
- Optimizing when the relational model is a problem. Sometimes developers can play with the normalization of data in SQL so much that the number of tables and relationships becomes too large. This may stop some write or read operations. In this case, due to many joins, no indexes will be saved. Therefore, it is worth turning to the NoSQL approach for data denormalization. Instead of millions of links, there will be a JSON form in one column. At the same time, if there were filterings, they would remain thanks to the new functions and syntaxes of the database.
There are many more examples of tasks that can be solved using this approach. First, there are Metadata Forms — complex dynamic forms. Second, BPMN Workflows, where all steps are described in JSON. And thirdly, this is CMS. Here, the user of the application is provided with the possibility of creating any dynamic content. In any case, it is always worth remembering: what worked well for someone, is not a fact that will work in another case. It is important to carefully consider different cases, to experiment, and then everything will work out.
You can read this article in Hungarian here.